
Kache - 散列式缓存
Kache缓存框架专注于优化高IO的Web应用中数据持久化层次的读写性能,并保证数据实时性,提高缓存数据库的空间利用率。
Kache强调业务与缓存解耦,通过方法为粒度进行动态代理实现旁路缓存,内部拥有特殊的参数编码器,屏蔽键值编码细节,以四个基本的CRUD注解和Status枚举或方法名匹配的形式对Kache表达方法的作用而面向抽象实现自动化处理。
Kache的缓存实现为Guava Cache+Redis+Lua,减少网络IO的消耗,且缓存分为索引缓存+元缓存,并在缓存存入时进行"Echo"操作,仅将尚未空缺的缓存存入而减少重复的序列化。在集中于热点的大数据量场景下,可以做到“接近无序列化程度”的缓存存入。
Kache适用广泛,组件实现都面向抽象,默认的实现都可以通过在Kache通过建造者模式时填入自定义的组件进行替换,可以做到MongoDB、IndexDB甚至是MySQL的缓存实现。并且提供额外的策略接口,允许用户对分布式、单机等环境进行对应的策略实现。
现有主流的GuavaCache是一个优秀的缓存框架,他出身于IT大头Google,其中对缓存的各种定义和操作都做出了非常合理的诠释与实现。
而类似的缓存框架也有J2Cache、Memcache、Ehcache等充分经受实践拷打的优秀开源框架。
甚至更甚者诸如SpringCache、AutoLoadCache这样的自动化缓存框架让用户脱离了缓存变更而手动处理缓存操作的繁琐业务流程。
而在这众多优先开源缓存框架之中,Kache存在的必要是什么?
论证这种缓存结构对于内存空间的最大化利用是否可行
Kache在缓存结构上对传统的缓存概念作出了“解耦”
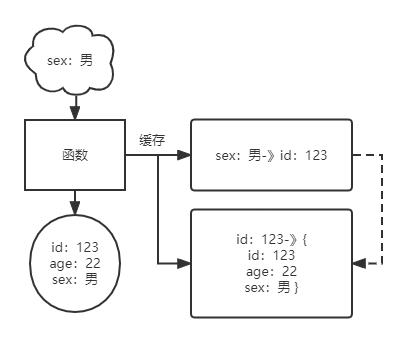
往常的缓存结构基本是将函数的参数作为Key,函数的结果作为Value
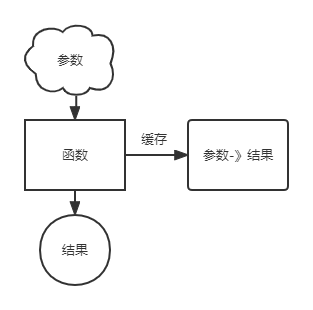
这样的缓存结构既简单,又满足了大多数情况下的使用。
只是在这种情况下产生了新的数据冗余问题:
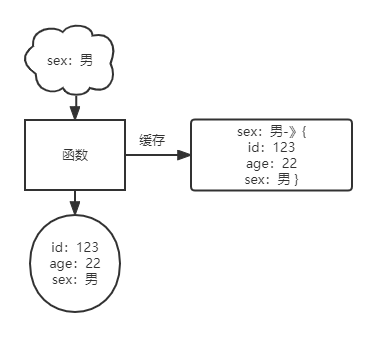
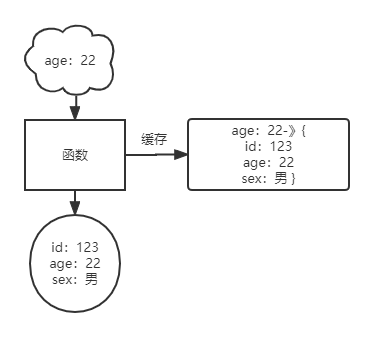
上图则为这种缓存结构下,不同参数指向同一数据的情况。
在类似进程间缓存时,像Java之中,这样的key-value使用类似HashMap的数据结构作为存储,故value和key为对象时都是以引用的形式存储,在合理的操作下并不会存在有重复的对象占用内存空间。
而在Redis这样常作为缓存的NoSQL数据库则并非如此。
在存入Redis时,数据往往都需要经过序列化;而序列化后的数据即使值是一致,但因为key的不同而导致同一份序列化数据会分别存储,造成数据冗余的占用。不仅在大对象序列化时会占用大量的cpu计算资源,也会导致有限的IO无法得到充分的利用。
这里引用一篇腾讯在知乎发布的一部有关于缓存文章的一句话:
Redis key大小设计: 由于网络的一次传输MTU最大为1500字节,所以为了保证高效的性能,建议单个k-v大小不超过1KB,一次网络传输就能完成,避免多次网络交互; k-v是越小性能越好
这也意味着,若是像增加结果为List这样的数据集缓存时,避免相同数据重复的序列化而导致序列化结果的空间变大,则能让缓存越小而越好。
而如何让数据减少重复序列化占用空间的同时保证数据信息的完整性?
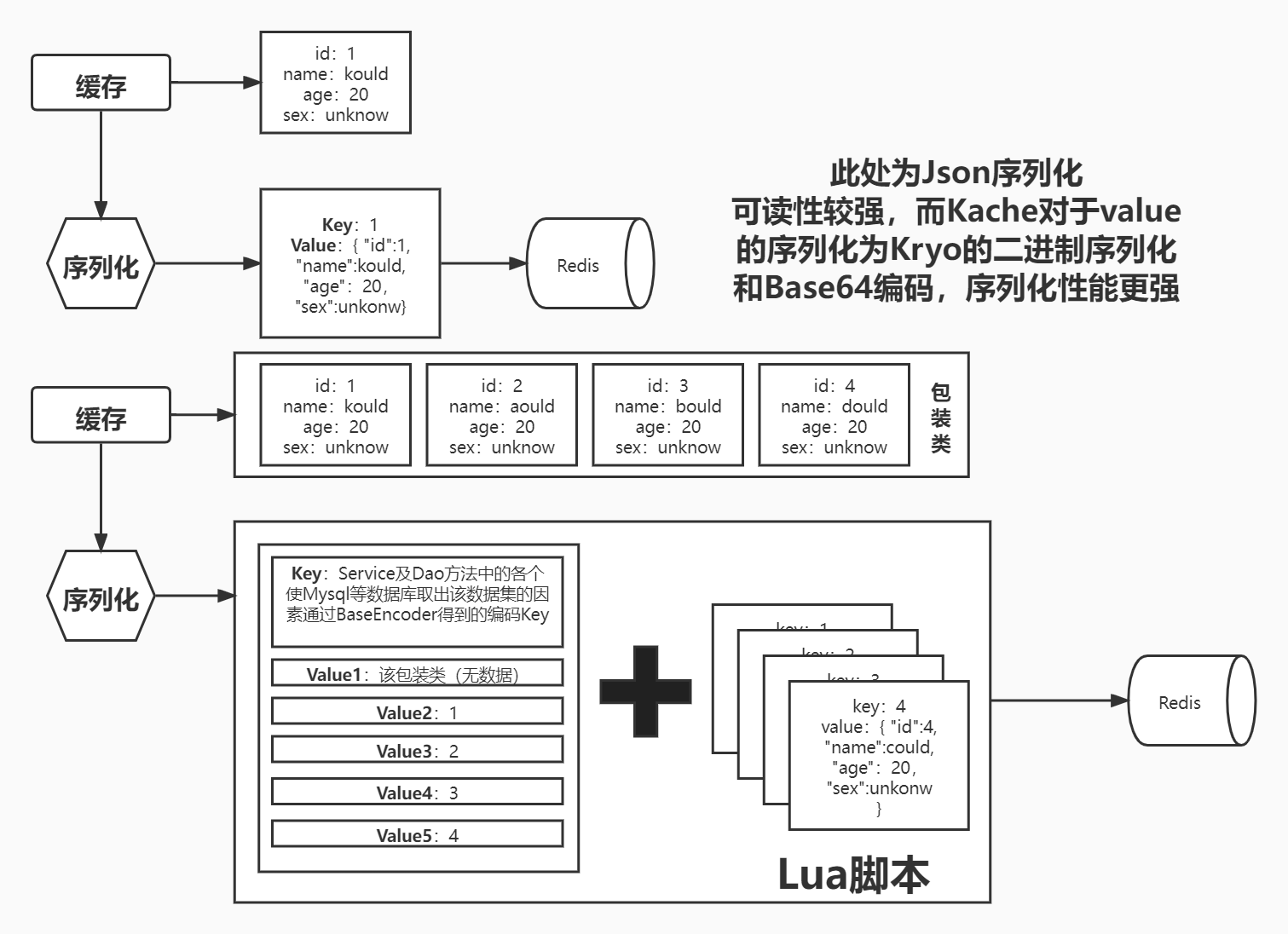
我的想法是,利用像Java进程对对象的引用一样,将单独的数据分别存入Redis之中,将id作为引用信息,使数据集中不包含具体的数据内容,取而代之则为各个数据的id。
这种方式将具体数据与参数进行解耦,将单独且具体的数据分布在Redis之中。
在面对刚才不同参数对应同一参数之间,做到了真正贴合实际引用逻辑。
这样的缓存结构之中,我称上缓存为索引缓存、下缓存为元数据缓存
而在Kache实现中更具体一些的逻辑如下:
当数据被条件读取时:
-
通过编码器将参数编码,作为索引缓存的Key
-
若对应的索引缓存不存在
-
解析数据集中元数据的个数与主键
-
拼接Echo脚本,用于查询Redis中所需的元数据缓存是否存在
-
若元数据都无或仅有部分:
-
将对应的数据集中元数据解析出,并将Redis中缺少的元数据与该索引数据一起保存在Redis之中
-
-
若元数据都有:
-
直接将索引缓存存入,不需要对具体数据再序列化且存入Redis之中。从而降低数据变动而导致缓存更新成本
-
-
-
若对应索引数据存在
- 将对应的参数通过编码器获取索引缓存的Key
- 通过Lua脚本在获取对应的索引缓存时,使用Redis的mget指令批量获取对应的元数据并进行填充,然后返回加工好的索引缓存(完整的序列化数据)
这样类型的缓存所能带来的特点:
-
数据集与单个数据分离
-
数据集删除的成本降低
-
当数据集被修改时,根据实际情况可能会重复利用之前所存储过的元数据缓存
-
最大化减少序列化的内容,做到不重复序列化一致数据
-
-
-
元数据以Id作为Key
- 为FindById方法直接提供对应的Key,可以直接获取对应元缓存
-
索引缓存仅有容器类的状态与元数据id集合
-
删除索引缓存而使缓存不删除元缓存数据
-
多个索引缓存共享一致的元缓存数据,去除数据冗余
-
-
对缓存依赖性较强,且数据变动较为频繁
-
Redis的基础建设较弱,服务器配置较低,对缓存的可用空间有限制
-
应用服务器CPU较差且IO密集
-
通过Id获取数据的方法使用较为频繁
-
瓶颈为数据库操作
-
大量重复数据
-
单个数据的内容大
-
数据体量大
若是满足以上大多数情况,则该缓存结构能给你带来相较于传统框架而言更为理想的性能。
该框架仅是此结构的一种实现,未经实际生产环境磨练。欢迎尝鲜
|- com.kould
|- annotaion 操作注解
|- DaoMethod 标记方法注解
|- api 对外调用接口
|- BeanLoad Kache内组件自动注入接口
|- Kache 控制面板
|- KacheEntity Entity实体类接口
|- codec 序列化编码器
|- KryoRedisCodec Kryo序列化编码器
|- ProtostuffRedisCodec Ptotostuff序列化编码器
|- core 读写处理逻辑
|- impl 实现
|- BaseCacheHandler 基础读写处理逻辑实现
|- CacheHandler 读写处理逻辑定义接口
|- encoder 键名编码器
|- impl 实现
|- BaseCacheEncoder 基础键名编码器实现
|- CacheEncoder 键名编码器定义接口
|- entity 包装实体
|- KacheMessage 摘要信息封装实体
|- KeyEntity 方法名摘要匹配实体
|- MethodPoint 方法代理封装实体
|- NullValue 空值实体
|- PageDetails 包装类型细节实体
|- Status 方法状态枚举
|- Type 方法类型枚举
|- function 函数式接口
|- SyncCommandCallback 同步命令函数
|- Strategy 删改策略
|- impl 实现
|- AmqpAsyncStrategy 基于AMQP的异步策略实现
|- DBFristStrategy 数据库优先同步策略实现
|- AsyncStrategy 异步策略接口定义
|- Strategy 策略接口定义
|- SyncStrategy 同步策略接口定义
|- inerceptor 拦截器
|- CacheMethodInerceptor 缓存方法代理拦截器
|- listener 监听器
|- impl 实现
|- MethodStatistic 方法统计计数器
|- StatisticsListener 统计监听器
|- StatisticsSnapshot 统计计数快照
|- CacheListener 缓存监听器定义
|- ListenerHandler 缓存监听处理器
|- manager 操纵管理器
|- impl 实现
|- BaseCacheManagerImpl 基础二级缓存封装操作实现
|- GuavaCacheManagerImpl 基于GuavaCache的进程缓存实现
|- RedisCacheManagerImpl 基于Redis的远程缓存实现
|- IBaseCacheManager 二级缓存封装操作接口定义
|- InterprocessCacheManager 进程缓存操作接口定义
|- RemoteCacheManager 远程缓存操作接口定义
|- properties 配置信息包装
|- DaoProperties Dao层配置
|- InterprocessCacheProperties 进程缓存配置
|- ListenerProperties 监听器配置
|- service Redis操作客户端
|- RedisService Redis封装实现
|- utils 工具
|- FieldUtils 属性反射工具
|- KryoUtils Kryo序列化工具
|- ProtostuffUtils Protostuff序列化工具
该Kache为原生JDK进行组件管理以支持Kotlin或scala等jdk语言使用,若是使用Spring框架请移步至:https://gitee.com/kroup/kache-spring
原生使用Kache的使用示例在test/java/com.kould.test/KacheTest中
1.pom文件引入:
<dependency>
<groupId>io.gitee.kould</groupId>
<artifactId>Kache</artifactId>
<version>1.8.9.INFORMAL_VERSION</version>
</dependency>2.缓存实体继承KacheEntity接口
@Data
@EqualsAndHashCode(callSuper = true)
@TableName("kork_article")
public class Article extends BasePO implements KacheEntity {
private static final long serialVersionUID = -4470366380115322213L;
@DataFactory(minLen = 10)
private String title;
private String summary;
@JsonAdapter(IdAdapter.class)
private Long authorId;
@JsonAdapter(IdAdapter.class)
private Long bodyId;
@JsonAdapter(IdAdapter.class)
private Long categoryId;
private Integer commentCounts;
private Long viewCounts;
private ArticleType weight;
@Override
public String getPrimaryKey() {
return getId().toString();
}
}3.对Mapper进行Kache的代理
Kache kache = Kache.builder().build();
// 需要对Kache进行init与destroy以保证脚本的缓存载入与连接释放
kache.init();
kache.destroy();
// 对Mapper进行动态代理,获取到拥有缓存旁路功能的新Mapper
// 示例:
ArticleMapper proxy = kache.getProxy(articleMapper, Article.class);4.其对应的Dao层的Dao方法添加注释:
- 持久化方法注解:@DaoMethod
- Type:方法类型:
- value = Type.SELECT : 搜索方法
- value = Type.INSERT : 插入方法
- value = Type.UPDATE : 更新方法
- value = Type.DELETE : 删除方法
- Status:方法参数状态 默认为Status.BY_Field:
- status = Status.BY_FIELD : 非ID查询方法
- status = Status.BY_ID : ID查询方法
- Class<?>[] involve:仅在Type.SELECT Status.BY_Field时生效:用于使该条件搜索方法的索引能够被其他缓存Class影响
- Type:方法类型:
@Repository
public interface TagMapper extends BaseMapper<Tag> {
@Select("select t.* from klog_article_tag at "
+ "right join klog_tag t on t.id = at.tag_id "
+ "where t.deleted = 0 AND at.deleted = 0 "
+ "group by t.id order by count(at.tag_id) desc limit #{limit}")
@DaoMethod(value = Type.SELECT,status = Status.BY_FIELD)
// 通过条件查询获取数据
List<Tag> listHotTagsByArticleUse(@Param("limit") int limit);
@DaoMethod(Type.INSERT)
// 批量新增方法(会导致数据变动)
Integer insertBatch(Collection<T> entityList);
}自定义配置或组件: PageDetails构造参数:
- 分页对象Class:Page.class
- 实体数据集合属性名:“records”
- 实体数据集合属性Class:List.class
// 以接口类型作为键值替换默认配置或增加额外配置
// 用于无额外参数的配置或组件加载
load(Class<?> interfaceClass, Object bean);
// 示例:注入MyBatis-Plus的包装类对象Page的PageDetails对象且关闭本地缓存
private final Kache kache = Kache.builder()
// 注册PageDeatils
.page(Page.class, "records", List.class)
// 关闭本地缓存
.load(LocalCacheProperties.class, new LocalCacheProperties(false, 0))
.build();Kache的原型的描述文章:
基于上述文章的主要变化为:
Service层缓存对于Dao层缓存来说产生一个问题:
- 缓存更新问题:Service支持DTO概念时,针对有一种PO却产生有不同的形态的缓存,最容易导致的问题是缓存删除、更新、新增时带来的一致性问题,对于PO结果有Page类对象封装的缓存更甚,对于缓存的利用率较低
而Dao缓存则能够去弥补上面所述的问题,是高性能的缓存所必不可少的
但于此同时Dao又会导致一系列实际开发上的问题
- 标准Dao的开发并不偏向业务化、不符合原先缓存Key逻辑
- Dao层有着一系列持久层框架带来的默认实现,难以对其命名规范的同一化
- Service层对Dao层耦合大、Dao的修改对系统稳定性是致命性的
可见与原先的缓存设计有着很大的冲突
于是使用了两层的AOP:
- ServiceAop获取Service方法信息摘要、通过ThreadLocal传递给DaoAop
- DaoAop获取Service层方法进行编码为Key,使用Key获取缓存的结果
以此避免同一Service方法下调用同一Dao方法但不同参数而引起的缓存冲突问题
- 主要通过注解的形式+切点的形式提供更好的兼容性
- 注解提高代码的可读性,且可以应对多种不同包名的这种细节性问题
- 一些框架的默认实现无法修改代码,则可以通过默认提供的切点来修改包名而兼容
- 降低对原项目的耦合,使更多第三方项目也能使用上
- 修复原本设计带来的一系列不足点的耦合问题
- 通过注解降低其业务代码侵入性,并简化使用
- 即使是NoSQL所带来的提升也仍然会导致网络IO的占用,为了更多的性能提升以及无用IO损耗则加入了进程间缓存的概念。
- 使用了二级缓存调度器,允许用户通过自定义二级缓存调度器去调度两个缓存的使用。
- 通过解析结果的持久类数据集,将持久类数据拆分并分别储存,将原包装类除去数据集后与数据集装填入List类型存入,去除实体数据与缓存索引的直接耦合
- 使实体数据原子化,加强数据一致性
- 减少缓存值重复,提高缓存的空间利用率
- 更直观观察到热点数据
- 散列开的单一持久化类有利于id查找
- Kache提供有KacheConfig.Status.BY_ID的状态属性用于标记直接id搜索,而实际的查找流程往往为:分页查询-》单一数据查询
- 如百度中搜索某一关键词后,点击其中提供内容中的一条。
- 散列化可以使在如上种情景下,不存在该关键词的缓存时,获取其分页数据时保存其单一实体缓存,使第二步的单一数据时必定命中缓存(点击其分页内容下),提高其缓存命中率且更加符合实际的应用场景
感谢@z_k_y耐心的测试使用和Bug反馈