design
Kenshin 是豆瓣开发的一个对磁盘友好的 Time Series Database,可以用来代替 Graphite 组件中的 Whisper, 使得 Graphite 单机就可以支撑百万级别的 Metrics。在本篇文章中我们将讲述一下 Kenshin 的设计和实现过程,以及对 Graphite 集群的改造。
在 2013 年的时候,为了错误隔离、服务自治等目标,豆瓣的工程团队决定对豆瓣的产品代码进行服务化改造,关于服务化的具体过程大家可以参考我们在 Qcon 2016 上的分享豆瓣的服务化体系改造,Qcon 网站提供 slide 的下载。
为了更好的监控服务化过程中各个服务的状态,我需要监控服务接口级别的 QPS、响应时间分布等数据,这将会带来了百万级的指标数量的增长;同时 Graphite 集群的磁盘 IO util 已经比较高(80% 左右), 为了应对即将到来的大量指标,以及减小磁盘 IO,我们制定了下面的目标,即单台机器可以支持:
- 指标数量 2 ~ 3 million
- 每个指标的更新周期 1s ~ 10s
- 内存使用 < 20 G
- 写入 IOPS < 1000
上面的目标中只描述了写操作,对于读操作在最初的目标中没有提及,不过读对于一个系统是至关重要的,因为如果读操作的性能如果不理想的话,那就没有了实际的用处。我们对 Kenshin 查询场景(读操作)有以下假设:
- 读操作少于写操作
- 一次读操作可能会有多个指标请求(甚至成百上千),需要在秒级别返回结果。
我们最开始想看看是否现成的系统可以满足我们的需求,当时主要考虑下面这三个系统:
OpenTSDB 是基于 HBase 的 Time Series Database,我们当时没有选用它的原因主要是:
- OpenTSDB 在当时支持的查询函数有限,查询接口不像 Graphite 方便易用。
- 依赖 HBase,对于豆瓣来说仅仅为指标存储而引入 HBase(Hadoop) 性价比不高。
不过 OpenTSDB 的基于 tag 的命名方式比较好,这也影响了 Kenshin 最初的设计:
sys.cpu.user host=webserver01 1356998400 50
sys.cpu.user host=webserver01,cpu=0 1356998400 1
sys.cpu.user host=webserver01,cpu=1 1356998400 0
sys.cpu.user host=webserver01,cpu=2 1356998400 2
sys.cpu.user host=webserver01,cpu=3 1356998400 0
InfluxDB 没有依赖,部署简单,本来是一个比较期待的可选对象,但是基于以下几点原因,最后放弃了它:
- 当时(14 年底)的时候,InfluxDB 有内存泄露的问题。
- InfluxDB 是 Schemaless 的,这是优点,但是也会占用更多的存储空间(可能会有 10X 的增加),因为每个记录都需要存储其 label 信息。
- 由于存储引擎的变化,导致 0.8.X 和 0.9.X(当时还没有发布)之间不兼容。
Whisper 是 Graphite 的存储引擎,它的优点有:
- 查询速度比较高效
- 支持自动的 Downsample
- 支持保留策略。
但是它的 IO 消耗比较大,主要是以下两个原因:
- 一个指标对应一个文件。Whisper 中一个指标对应一个文件,而指标系统单机需要支持百万个指标,这些指标的更新频率是 1s~10s, 这意味着每秒有百万的写操作(当然这可以通过内存 batch 的方式得到缓解,但是写操作的量也是比较可观的)。另外,在查询时,一般我们会同时查多个指标(几百个),这也意味着一个查询请求需要几百个读文件的操作。
- archive 之间的级联写(写放大)。Whsiper 文件的结构是分为多个 archive 的,代表不同的时间粒度,当更新较高时间粒度(如 10s)的数据时会触发较低时间粒度(如 60s)的数据的更新(由 xFilesFactor 参数控制,后面我们还会介绍这个参数),从而导致一个指标的一次更新操作,可能会发展成多次更新操作。
在考虑了上面系统的调研结果,以及我们当时的监控系统架构后,我们决定在 Whisper 的模型基础上改造,并创建了 Kenshin 项目,其名称来源于电影《浪客剑心》。
基本思路是:
- 合并指标文件
- 减少 archive 之间的更新操作
目标是:
- 减小 IOPS
- 保持查询速度
- 兼容 Graphtie Web
接下来我们分别来看看如何实现前面提到的两个基本思路。
Whisper 的设计中一个指标对应一个文件,这不仅会增加 IO 的操作次数,还会产生大量的小文件(备份会很慢)。另一方面,在豆瓣的使用场景中,我们查询时一般会读取多个指标,例如:
stats.counters.web.*.bandwidth.rate
servers.*.doubanmemcache.mc-server*.get_time
所以一个基本想法就是尽量把这些会同时查询的指标合并在一起,每 N 个指标合并成一个文件。相应的指标名称也要改一下,从单一的点分格式转换为 name + tag 的方式,然后我们就可以把 name 相同的合并在一起。下面就是一个指标名称转换的例子,其中 stats.counters.web.bandwidth.rate 是指标的 name,app=movie 是指标的 tag(tag 可以有多个)。
stats.counters.web.movie.bandwidth.rate
|
V
stats.counters.web.bandwidth.rate app=movie
这个思路虽然挺好,不过对于现有的指标体系改变较大,它要求指标系统的用户在发送指标前,就设计好指标体系结构,以及未来会怎样查询,这就像申请 MySQL 表似的,开发者需要向 DBA 说明表的结构,以及可能的查询场景。然而实际中用户倾向于收集更多的指标,因为一个系统上线的时候,用户有时候也不知道应该看什么指标,所以会把这个系统收集到的指标全部发给指标系统。
最后,我们使用了下面这样简单的假设:「同时创建的指标(schema 必须相同),可能会一起查询」。 比如,我们新加入一个服务器时,关于这个服务器的所有指标会同时创建,而且这些指标也很可能会被一起查询。有了这个假设我们就解决了哪些指标应该合并在一起的问题,接下来,我们看看多个指标如何合并在一起,即 Kenshin 的文件结构是怎么样的。

Kenshin 的文件结构整体上和 Whisper 的文件结构类似。首先是 Header 部分,包含了 Kenshin 文件的元信息,然后后面是多个 archive 部分。每个 archive 是一个独立的存储区间,存储了某种时间粒度的数据,它由一系列的 datapoint 构成,每个 datapoint 的格式是 (timestamp, value1, value2, value3, ..., valueN),其中 N 表示一个 Kenshin 文件中包含了多少个指标。这些 datapoint 在逻辑上是一个二维的结构,每一行表示一个指标,每一列表示一个时间时刻。
由于我们把多个指标合并成了一个文件,而且选择的是按时间戳对齐的方式(这种方式有利于写操作)顺序写入文件。所以当我们读取一个指标的数据时,就会读取比之前更多的数据,从而影响读取速度。为了解决这个影响,我们利用了 cache 来缓存额外读取出来的那些指标,我们前面提到过,多数查询会读取多个指标,所以在读取后面的指标时有很大可能性可以直接命中缓存,从避免了文件的操作,这样就会提高查询速度。
前面我们提到 kenshin 文件中包含了 N 个指标,那么这个 N 应该如何确定呢?N 的最优值是跟磁盘的性能相关的,是需要实际测试的,不过我们对 N 的取值有一个基本的预期:
- N 取值越大,写入的 IO 操作会越少,但是读取的速度会越慢。
- N 取值越小,写入的 IO 操作会变多,读取性能会高效,当 N 等于 1 时就退化成了 Whisper 的方式。
- 另外,SSD 有写放大的特性(SSD 最小的写入单位是 page,通常大小为 KB 级别),所以 N 的值不能太小。
我们的目标是减小写入 IO 次数,同时保持查询的速度和 Whisper 相当。为此我们做了下面的实验:
- 磁盘:合伯 520 SSD(1TB)
- 查询:选了线上一个比较复杂的查询,会同时查 1220 个指标
- 我们使用了 memcached 作为缓存
试验中需要测试的变量:
A: 从文件中读取一天的数据所需要的时间(注意,由于一个 Kenshin 文件包含 N 个指标,所以一次文件读取会同时把 N 个指标的数据读取出来)
B: 把 A 中的数据按照各个指标进行拆分,然后 set 到 memcached 所需要的时间
C: 从 memcached 中 get 单个指标所需要的时间
P: 一次查询中缓存命中概率(对于我们例子,其缓存命中率为 1028/1220=0.84)
那么这次查询单个指标的平均时间为:
V: ((W/N) * (A+B+C) + ((1-P)*(A+B+C) + P*C)(W-W/N)) / W
由于我们需要查询 W 个指标,所以至少需要 W/N 次文件操作,上面的公式中分子的前半部分表示的就是这些文件操作 所需要的时间;后半部分计算了缓存命中率为 P 时读取后续指标所需要的时间。由于 W 会被约掉,所以下面不再关心 W。我们现在的目标就是在 N 取不同值时看 V 的值,然后选一个比较满意 N 值。
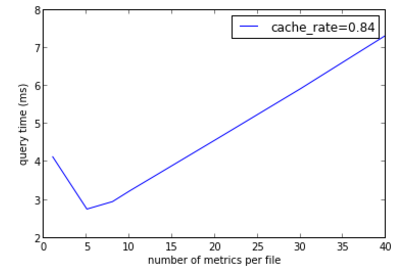
图中的横坐标是 N 的取值,纵坐标是查询时间,在平衡了前面提到的因素后,我们选择了 N=8 这个值。
Whipser 中有一个比较重要的参数 xFilesFactor(后面简称为 xff)。在继续阅读之前,请确保你已经阅读了链接中给出的文章。
假设指标 A 有两个 archive:
archive0: 10s 精度,保留 12h
archive1: 60s 精度,保留 2d
那么 archive0 的 6 个点会聚合为 archive1 的 1 个点,假设聚合函数为 average,xff 为 0.5,那么从 arvhive0 的第 3 个点开始,每次到达一个点都要更新下 archiv1 的点,如图:
t1:
+---+---+---+---+---+---+
| 1 | 2 | 3 | | | | # 10s 粒度的点
+-----------------------+
+-----------------------+
| 2 | # 60s 粒度的点
+-----------------------+
t2:
+---+---+---+---+---+---+
| 1 | 2 | 3 | 4 | | |
+-----------------------+
+-----------------------+
| 2.5 |
+-----------------------+
t3:
+---+---+---+---+---+---+
| 1 | 2 | 3 | 4 | 5 | |
+-----------------------+
+-----------------------+
| 3 |
+-----------------------+
t4:
+---+---+---+---+---+---+
| 1 | 2 | 3 | 4 | 5 | 6 |
+-----------------------+
+-----------------------+
| 3.5 |
+-----------------------+
以这个例子来说,archive1 中的一个点是由 archive0 中 6(60/10)个点聚合而来,xff 的含义就是这个 6 个点中来多大比例时,我们去生成 archive1 中的点。xff 的取值范围是 [0, 1],默认是 0.5。
- xff 的值越小对 IO 操作越多。
- xff 的值越大 archive1 中的空洞(值为 null 的点)越多。
xff 还有一个问题是,假设新来了这个指标,它的发送频率是 30s 一个点,那么在现有的 schema 下它只能写到 archive0 中,而无法更新到 archive1 中去。这时只能针对新指标添加一个新的 schema,当指标多了之后,这个是比较麻烦的。
为了减小 IO 操作,我们倾向于让 xff 越大越好,甚至可以超过 1(此时 xff 的含义就变了,不再是前面提到的比例的含义,而是说 archive0 中累积了多少个 archive1 中的点的时候,批量往 archive1 中更新),但是此时需要解决空洞和数据延迟的问题。为此我们做了两个「假设」:
- 查询长期趋势时可以容忍近期的数据延迟到达,比如在看一个月的趋势时,对最近一个小时内的数据延迟可以容忍。如果要看最近的数据,可以在精度较高的 archive(如例子中的 archiv0)上查看。
- 聚合(Downsample)触发时,只要 archive0 中有一个点,我们就允许其向 archive1 更新。该假设解决了前面提到的空洞问题。
基于上面的假设我们改变了 xff 的含义,即 xff 表示 archive0 累积了多少个 archive1 中的点时才去做聚合操作,并批量更新 archive1 中的点。所以此时 xff 的取值范围是 [0, +∞)。显然 xff 的值越大,IO 操作会越少,但是 downsample 更新的延迟会越大。在我们的使用场景中我们把 xff 的值设置为 20。
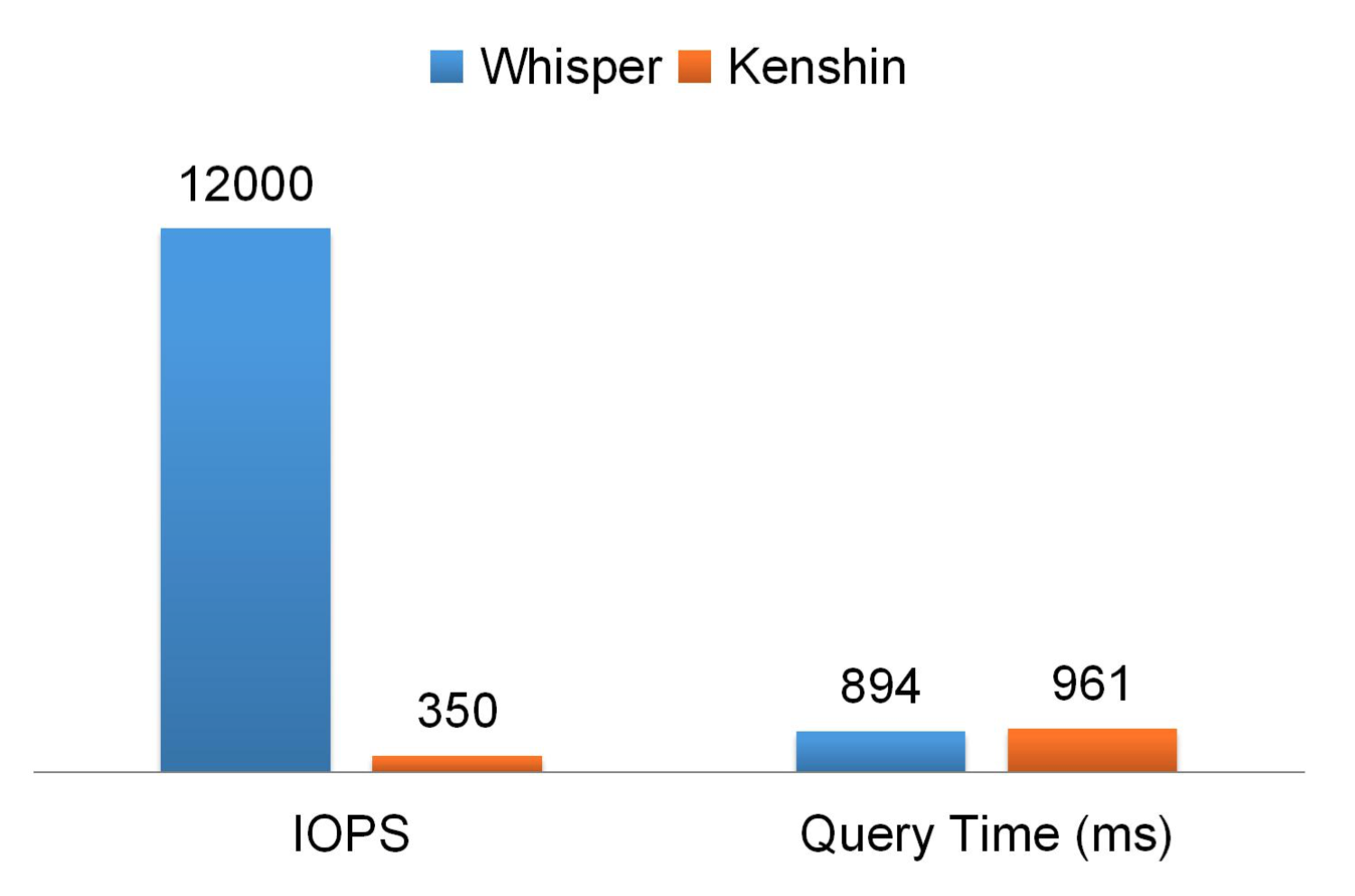
在解决了上面提到的那些问题之后,实现 Kenshin 相对是一件比较简单的事情,实现过程中主要是参考了 Whisper 以及 Carbon(当时我们内部用的 0.9.10 版本)。下图是 Kenshin 性能,从中可以看到我们把 IOPS 降低了大约 40 倍,同时查询时间基本不变。
在 Kenshin 上线了之后,我们也对 Graphite 集群做了调整,下图是旧的 Graphite 集群结构:

我们用了两个 server,它们是一个 mirror 的结构,每个 server 上都有全量的数据,共同负担查询请求,查询部分没有在这里画(每个 server 上还有一个 graphite-web 实例)。这种架构的缺点是第二层的 relay 不能线性的扩容。
为此我们简化了 relay 的结构,把它调整成了一层了结构:

现在的架构下 relay 之间是对等的,当 relay 出现瓶颈的时候,直接在加一个 relay 就行。
另外,为了数据的线性扩容,我们预先把 Kenshin 数据分了 16 个 Hash 桶,每个桶是 2 副本,目前分布在两个 server 上。图中的 Rurouni Cache 是 Kenshin 的 deamon 进程,负责缓存以及写 Kenshin 文件。目前的数据扩容方式主要是下面两种:
- 我们目前是把 16 个 Hash 桶放在一个 server 上的,随着数据量的增加,这个 16 个 Hash 桶在一个 server 放不下时,我们需要新加节点,然后把其中一些桶迁移过去。
- 如果数据量继续增加,一个 server 上放不下一个 Hash 桶时,我们就需要对数据进行 rehash 操作。
我们在 QCon 2016 上分享了豆瓣百万级指标监控实践。其中比较详细的介绍了 Graphite 集群的性能、数据迁移的步骤等信息,欢迎大家参考。