runtime: CPU bound goroutines cause unnecessary timer latency #38860
Comments
|
Thanks for the very detailed analysis. I think this has been fixed on tip by https://golang.org/cl/216198. Would it be possible to see if you get better results when running tip rather than 1.14? Thanks. |
|
The above test fails on tip as of 4c003f6 built just now. I am not sure I understand how https://go-review.googlesource.com/c/go/+/216198/ would help since it fixed an issue with goroutines returned by the poller, but the test code above does not involve the poller that I can see. |
|
Well, it was a more general fix really, but thanks for testing it. |
|
Change https://golang.org/cl/232199 mentions this issue: |
|
The obvious fix would be something like https://golang.org/cl/232199. Your test fails for me on my system with both 1.13 and tip, but with this change the delays seem to be smaller with tip. Can you see how that change does on your system? Thanks. |
|
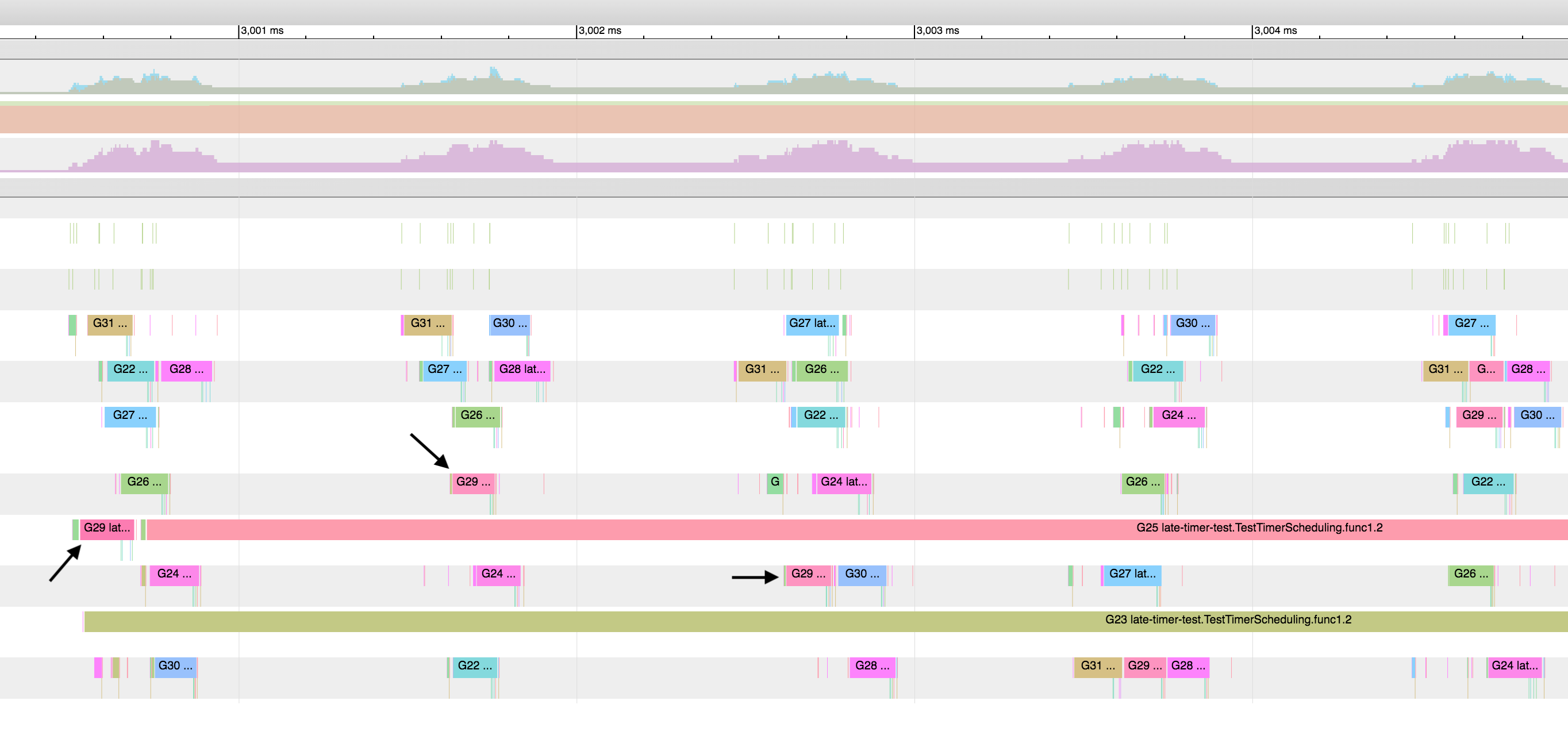
Yes, I have a fix similar to yours staged here going through OSS contribution review that I hope I can share soon. The test passes consistently with your change on my linux server (10 out of 10 tries) and passes with roughly the same frequency as Go 1.13 does on my Mac (9 out of 10 for both just now). More definitively the execution trace shows the timers not getting ignored while the longer task runs. Here is what it looks like. I used the search bar to highlight all instances of one G and you can see around the 2,000ms mark that it gets stollen from the first P to the second P and then on its next wakeup gets stollen by the third P, both times while its former P runs a longer task. After two more iterations it ends up on the last P for several ticks in a row.
Here is one of the timing histograms.
This change makes a clear improvement. |


|
Change https://golang.org/cl/232298 mentions this issue: |
|
My attempt to fix this issue is in https://golang.org/cl/232298. @ianlancetaylor, it may have less overhead than your first draft because it only calls |
|
Also, I copied your sentence referencing the CL that reduced timer lock contention into my commit message. I was wondering when that optimization was added, but didn't know how to find it. |
|
@aclements @mknyszek There are two slightly different CLs to address this issue, in https://golang.org/cl/232199 and https://golang.org/cl/232298. Any opinions on the right approach here? Thanks. |
|
https://golang.org/cl/232199 (which I just +2d) seems much simpler and lower risk than https://golang.org/cl/232298. I'm not clear what the benefits of https://golang.org/cl/232298's approach are. |
|
FWIW, I've been working on this issue for the last couple weeks, and have found the issue is not fully resolved by either of the two CL's linked above. I will have an update to my CL with a more comprehensive solution soon that includes benchmarks to demonstrate the benefit. |
|
Brief explanation of why neither CL fixes this issue: They both still have scenarios in which a timer can starve while there are idle P's until sysmon wakes up and checks timers, but for applications that typically have idle P's most of the time, sysmon will only wake up every 10ms. 10ms timer latency is a significant regression from previous versions of Go and insufficient for our application. I believe the update to my CL I plan to post soon eliminates the scenarios in which a timer can starve while there are idle P's. |
|
Thanks for looking into this. Note that at this stage of the release process any change to the runtime has to be very minimal and very safe. |
|
Change https://golang.org/cl/235037 mentions this issue: |
|
@ianlancetaylor I understand that this may not make it for Go 1.15. I was a bit surprised when it was added to that milestone given the issue was filed right at code freeze time. That does not change my motivation to get this resolved. If it gets held for Go 1.16, so be it. Also, I got my wires crossed updating my CL. The link in the preceding comment is for the wrong CL (my mistake), but I did get the proper CL updated eventually. So for anyone reading this, the proper CL is https://golang.org/cl/232298. |
|
@ChrisHines said the fix that was pushed doesn't resolve his issue, so I think this should be reopened? Also, should the new fix be backported to 1.14? |
|
Chris, it would be helpful to have the analysis you posted to Gerrit on May 22nd copied into this thread. It's hard to find things in Gerrit. Thanks! |
|
Sure @networkimprov. Here is a copy/paste of that from https://golang.org/cl/232298: Patch set 4 is a more comprehensive fix for issue #38860. I converted the test in patch set 3 to a benchmark and added an additional benchmark. I spent a lot of time studying the history of proc.go and its predecessors proc1.go and proc.c to do my best to maintain the proper invariants. I found the workings of sysmon particularly mysterious in the beginning. I had a basic idea what it was for, but didn't understand (and maybe I still don't) the choices behind when to reset the idle and delay variables. Reading through the history it seems to me that not reseting them when waking for a timer is appropriate, but I would be happy to learn more about that if anyone has any references I can look at. I added a comment block in sysmon to try and help future readers avoid having to dig through the history to understand the rules sysmon has but won't profess that I got that all right, please double check that carefully. The commit message on 156e8b3 in particular helped me understand that part of the scheduler so I tried to capture those ideas the best I could. I view the choice of whether to steal timers before or after looking at runnext as flexible. It seems intuitive to me to steal timers first and I tried to describe my rationale in the comment there, but would happily restore it to checking timers last if someone makes the case for it. Adding the call to wakep in wakeNetPoller is necessary to avoid starving timers if there is no thread in the netpoller to wake. It should also have the same or less cost as the call to netpollBreak in the other half of the function. Here are the results of running the timer related benchmarks from the time package and the new benchmarks added here with Go 1.13.9, 1.14.2 and this patch all on the same machine back to back. All benchmarks were run with -count=10 From these results we can see that Go 1.14 significantly improved the existing time package benchmarks compared to Go 1.13, but it also got much worse on the latency benchmarks I have provided. This patch does not recover all of the latency that was lost, but most of it. My anecdotal observation here is that it appears the Linux netpoller implementation has more latency when waking after a timeout than the Go 1.13 timerproc implementation. Most of these benchmark numbers replicate on my Mac laptop, but the darwin netpoller seems to suffer less of that particular latency by comparison, and is also worse in other ways. So it may not be possible to close the gap with Go 1.13 purely in the scheduler code. Relying on the netpoller for timers changes the behavior as well, but these new numbers are at least in the same order of magnitude as Go 1.13. Somewhat surprisingly the the existing benchmarks improved somewhat over Go 1.14.2. I don't know if that's a result of this patch or other improvements to the runtime or compiler since 1.14.2. Here is just the 1.14.2 -> patch comparison I don't know why the 300µs/8-tickers case contradicts the rest of the trend. That's something to investigate. With regards to issue #25471 that Ian expressed concern about making worse. I get these results using the methodology described in that issue: Go 1.13.9 Go 1.14.2 Patch set 4 Not a watershed improvement, but somewhat better and certainly no worse. I believe most of the improvement here is due to not forcing sysmon back into high frequency mode after each wakeup from a timer. |
|
Also, please reopen this issue. The CL that claims to have fixed it is only a partial fix. |
|
Sorry, that was my mistake. I meant to update the CL description, but forgot. |
|
@gopherbot please backport to 1.14. This is a regression with a simple fix. (It may have a more complex fix, too, but that won't land until 1.16.) |
|
Backport issue(s) opened: #39383 (for 1.14). Remember to create the cherry-pick CL(s) as soon as the patch is submitted to master, according to https://golang.org/wiki/MinorReleases. |
|
Kindly chiming in to ask if we should re-milestone this for Go1.15 as Ian's CL landed, and he re-opened this issue, but I thought perhaps we'll complete that work in Go1.16? |
|
Thanks, this is for 1.16 now. |
|
CockroachDB upgraded to Go 1.14 about three weeks ago, and since then, we've seen what appears to be some concerning fallout from this issue. In a few of our nightly tests running on GCP VMs with 4 vCPUs, we push machines up to around 80%-85% of their compute capacity. We've run this kind of test for years without issue. Since upgrading to Go 1.14, we've seen that in this state, tickers can be starved for excessively long durations, orders of magnitude longer than has been discussed thus far in this issue. For context, each node in a CockroachDB cluster heartbeats a centralized "liveness" record to coordinate a notion of availability. This heartbeating is driven by a loop that uses a ticker to fire once every 4.5 seconds. Upon firing, the expiration of the node's liveness record is extended by 9 seconds. Our testing in cockroachdb/cockroach#50865 is showing that once a machine is sufficiently loaded (~85% CPU utilization), this heartbeat loop can stall for long enough to result in a node's liveness lapsing. Specifically, we see cases where the ticker which is configured to fire every 4.5 seconds takes over 10 seconds to fire. This is easily reproducible on Go 1.14 and not at all reproducible on Go 1.13. I explored patching 9b90491 into the Go 1.14 runtime and observed that it did help, but did not eliminate the problem entirely. Instead of our tests failing reliably every time, they only fail about a third of the time. This corroborates @ChrisHines's findings – the patch results in a clear improvement but is only a partial fix. These findings may also bring into question whether we consider this to be a performance regression or a bug, and by extension, whether a backport for the partial fix is warranted (#39383). I sympathize with the sentiment that this issue is revealing a performance regression in a construct that provides no hard performance guarantees. And yet, starvation on the order of 10s of seconds seems entirely different than that on the order of 10s of milliseconds. |
|
@nvanbenschoten Thanks for the report. As we are very close to the 1.15 release at this point, it's unfortunately too late to fix this for 1.15. I think it would be OK to backport https://golang.org/cl/232199 to the 1.14 branch if that makes things better. Are your goroutine largely CPU bound? Does it change anything if you add an occasional call to |
Understood.
We would appreciate that. While it's not a complete fix, it does make a measurable improvement.
In this test, yes. But I'm surprised they are running for this long without returning to the scheduler. I'm trying to get a handle on whether I can narrow down which goroutine is causing issues. If I can, I'll play around with manually yielding on occasion and see if that clears up the starvation. |
Reverts most of cockroachdb#50671. We upgraded from Go1.13.9 to Go1.14.4 on June 29th in cockroachdb#50671. Since then we've seen a fair amount of fallout in our testing and build system. Most of this has been reasonable to manage. However, we recently stumbled upon a concerning regression in the Go runtime that doesn't look easy to work around. Go1.14 included a full rewrite of the runtime timer implementation. This was mostly a positive change, but shortly after the 1.14 release, reports started coming in of multi-millisecond timer starvation. This is tracked in this upstream issue: golang/go#38860. A few months later, when we upgraded Cockroach to use 1.14, some of our tests started hitting the same issue, but in our tests, the starvation was much more severe. In cockroachdb#50865, we saw instances of multi-second timer starvation, which wreaked havoc on the cluster's liveness mechanisms. A partial fix to this runtime issue has landed for Go 1.15 (https://go-review.googlesource.com/c/go/+/232199/) and may be backported to 1.14, but there is currently no ETA on the backport and no guarantee that it will even happen. A more robust fix is scheduled for 1.16 and the PR is still open in the Go repo (https://go-review.googlesource.com/c/go/+/232298/). As we approach the CockroachDB 20.2 stability period, it seems prudent to avoid the risk of downgrading our Go runtime version too late. For that reason, Alex, Andy K, Peter, and I recommend the following course of actions: * Downgrade 20.2 to 1.13 immediately, so we go into the stability period with the right version of Go. * Schedule the subsequent improvements to non-preemptable loops in CockroachDB itself in 21.1. * At the beginning of the 21.1 cycle upgrade CRDB to 1.15 and effectively skip 1.14 all together. This PR addresses the first of these steps. While here, it also picks up the latest patch release of Go 1.13, moving from 1.13.9 to 1.13.14. Checklist: * [X] Adjust version in Docker image ([source](./builder/Dockerfile#L199-L200)). * [X] Rebuild and push the Docker image (following [Basic Process](#basic-process)) * [X] Bump the version in `builder.sh` accordingly ([source](./builder.sh#L6)). * [X] Bump the version in `go-version-check.sh` ([source](./go-version-check.sh)), unless bumping to a new patch release. * [X] Bump the go version in `go.mod`. You may also need to rerun `make vendor_rebuild` if vendoring has changed. * [X] Bump the default installed version of Go in `bootstrap-debian.sh` ([source](./bootstrap/bootstrap-debian.sh#L40-42)). * [X] Replace other mentions of the older version of go (grep for `golang:<old_version>` and `go<old_version>`). * [ ] Update the `builder.dockerImage` parameter in the TeamCity [`Cockroach`](https://teamcity.cockroachdb.com/admin/editProject.html?projectId=Cockroach&tab=projectParams) and [`Internal`](https://teamcity.cockroachdb.com/admin/editProject.html?projectId=Internal&tab=projectParams) projects. (I will do the last step after this has merged) Release note (general change): Revert the Go version back to 1.13.
Reverts most of cockroachdb#50671. We upgraded from Go1.13.9 to Go1.14.4 on June 29th in cockroachdb#50671. Since then we've seen a fair amount of fallout in our testing and build system. Most of this has been reasonable to manage. However, we recently stumbled upon a concerning regression in the Go runtime that doesn't look easy to work around. Go1.14 included a full rewrite of the runtime timer implementation. This was mostly a positive change, but shortly after the 1.14 release, reports started coming in of multi-millisecond timer starvation. This is tracked in this upstream issue: golang/go#38860. A few months later, when we upgraded Cockroach to use 1.14, some of our tests started hitting the same issue, but in our tests, the starvation was much more severe. In cockroachdb#50865, we saw instances of multi-second timer starvation, which wreaked havoc on the cluster's liveness mechanisms. A partial fix to this runtime issue has landed for Go 1.15 (https://go-review.googlesource.com/c/go/+/232199/) and may be backported to 1.14, but there is currently no ETA on the backport and no guarantee that it will even happen. A more robust fix is scheduled for 1.16 and the PR is still open in the Go repo (https://go-review.googlesource.com/c/go/+/232298/). As we approach the CockroachDB 20.2 stability period, it seems prudent to avoid the risk of downgrading our Go runtime version too late. For that reason, Alex, Andy K, Peter, and I recommend the following course of actions: * Downgrade 20.2 to 1.13 immediately, so we go into the stability period with the right version of Go. * Schedule the subsequent improvements to non-preemptable loops in CockroachDB itself in 21.1. * At the beginning of the 21.1 cycle upgrade CRDB to 1.15 and effectively skip 1.14 all together. This PR addresses the first of these steps. While here, it also picks up the latest patch release of Go 1.13, moving from 1.13.9 to 1.13.14. Checklist: * [X] Adjust version in Docker image ([source](./builder/Dockerfile#L199-L200)). * [X] Rebuild and push the Docker image (following [Basic Process](#basic-process)) * [X] Bump the version in `builder.sh` accordingly ([source](./builder.sh#L6)). * [X] Bump the version in `go-version-check.sh` ([source](./go-version-check.sh)), unless bumping to a new patch release. * [X] Bump the go version in `go.mod`. You may also need to rerun `make vendor_rebuild` if vendoring has changed. * [X] Bump the default installed version of Go in `bootstrap-debian.sh` ([source](./bootstrap/bootstrap-debian.sh#L40-42)). * [X] Replace other mentions of the older version of go (grep for `golang:<old_version>` and `go<old_version>`). * [ ] Update the `builder.dockerImage` parameter in the TeamCity [`Cockroach`](https://teamcity.cockroachdb.com/admin/editProject.html?projectId=Cockroach&tab=projectParams) and [`Internal`](https://teamcity.cockroachdb.com/admin/editProject.html?projectId=Internal&tab=projectParams) projects. (I will do the last step after this has merged) Release note (general change): Revert the Go version back to 1.13.
52348: build: downgrade to Go 1.13 r=nvanbenschoten a=nvanbenschoten Reverts most of #50671. We upgraded from Go1.13.9 to Go1.14.4 on June 29th in #50671. Since then we've seen a fair amount of fallout in our testing and build system. Most of this has been reasonable to manage. However, we recently stumbled upon a concerning regression in the Go runtime that doesn't look easy to work around. Go1.14 included a full rewrite of the runtime timer implementation. This was mostly a positive change, but shortly after the 1.14 release, reports started coming in of multi-millisecond timer starvation. This is tracked in this upstream issue: golang/go#38860. A few months later, when we upgraded Cockroach to use 1.14, some of our tests started hitting the same issue, but in our tests, the starvation was much more severe. In #50865, we saw instances of multi-second timer starvation, which wreaked havoc on the cluster's liveness mechanisms. A partial fix to this runtime issue has landed for Go 1.15 (https://go-review.googlesource.com/c/go/+/232199/) and may be backported to 1.14, but there is currently no ETA on the backport and no guarantee that it will even happen. A more robust fix is scheduled for 1.16 and the PR is still open in the Go repo (https://go-review.googlesource.com/c/go/+/232298/). As we approach the CockroachDB 20.2 stability period, it seems prudent to avoid the risk of downgrading our Go runtime version too late. For that reason, @lunevalex, @andy-kimball, @petermattis, and I recommend the following course of actions: * Downgrade 20.2 to 1.13 immediately, so we go into the stability period with the right version of Go. * Schedule the subsequent improvements to non-preemptable loops in CockroachDB itself in 21.1. * At the beginning of the 21.1 cycle upgrade CRDB to 1.15 and effectively skip 1.14 all together. This PR addresses the first of these steps. While here, it also picks up the latest patch release of Go 1.13, moving from 1.13.9 to 1.13.14. Checklist: * [X] Adjust version in Docker image ([source](./builder/Dockerfile#L199-L200)). * [X] Rebuild and push the Docker image (following [Basic Process](#basic-process)) * [X] Bump the version in `builder.sh` accordingly ([source](./builder.sh#L6)). * [X] Bump the version in `go-version-check.sh` ([source](./go-version-check.sh)), unless bumping to a new patch release. * [X] Bump the go version in `go.mod`. You may also need to rerun `make vendor_rebuild` if vendoring has changed. * [X] Bump the default installed version of Go in `bootstrap-debian.sh` ([source](./bootstrap/bootstrap-debian.sh#L40-42)). * [X] Replace other mentions of the older version of go (grep for `golang:<old_version>` and `go<old_version>`). * [ ] Update the `builder.dockerImage` parameter in the TeamCity [`Cockroach`](https://teamcity.cockroachdb.com/admin/editProject.html?projectId=Cockroach&tab=projectParams) and [`Internal`](https://teamcity.cockroachdb.com/admin/editProject.html?projectId=Internal&tab=projectParams) projects. (I will do the last step after this has merged) Release note (general change): Revert the Go version back to 1.13. Co-authored-by: Nathan VanBenschoten <nvanbenschoten@gmail.com>
|
Now that the Go 1.16 tree is open I would like to return attention to this issue. I have responded to all comments on https://go-review.googlesource.com/c/go/+/232298 posted to date. Please review and let me know if you have any additional questions or concerns. |
Change the scheduler to consider P's not marked for preemption as potential targets for timer stealing by spinning P's. Ignoring timers on P's not marked for preemption, as the scheduler did previously, has the downside that timers on that P must wait for its current G to complete or get preempted. But that can take as long as 10ms. In addition, this choice is only made when a spinning P is available and in timer-bound applications it may result in the spinning P stopping instead of performing available work, reducing parallelism. In CL 214185 we avoided taking the timer lock of a P with no ready timers, which reduces the chances of timer lock contention. Fixes golang#38860 Change-Id: If52680509b0f3b66dbd1d0c13fa574bd2d0bbd57
What version of Go are you using (
go version)?Does this issue reproduce with the latest release?
Yes.
What operating system and processor architecture are you using?
What did you do?
Run the following test built with Go 1.13.9 and Go 1.14.2:
What did you expect to see?
All tests pass on both versions of Go.
What did you see instead?
On the 56 CPU Linux server with nothing else of significance running:
I get similar results on macOS although we don't deploy the application on that platform.
Additional Background
I initially discovered this problem while testing a Go 1.14 build of our application to see if we could upgrade to the newest version of Go on the project. This is the same application described in #28808 and in my Gophercon 2019 talk: Death by 3,000 Timers. Unfortunately I discovered that this regression in Go 1.14 forces us to stay with Go 1.13 for that application.
Note that our application can tolerate late wake ups as long as they are not too late. The grace period of four intervals on the high frequency timer implements that idea. I derived the constants in the test from our real world requirements, rounded off to keep the numbers simple.
The
mixedFreqtest case above best models our application's work load. It spends most of its time sending UDP packets on the network at a target bitrate (the high frequency work) but must also perform some heavier tasks to prepare each new stream of UDP packets (the low frequency work).I added the test cases with homogenous workloads to verify that the issue isn't a fundamental performance issue, but rather an emergent behavior of the scheduler.
Analysis
As you can see, the test code above uses
runtime/traceannotations. We have similar annotations in our production code. Analyzing execution traces from either source leads to the same conclusion. The runtime scheduler in Go 1.14 introduces unnecessary timer latency for this kind of application by not stealing timers from non-preemptable P's as described in the following code comment.go/src/runtime/proc.go
Lines 2164 to 2171 in 96745b9
Evidence
Here is an execution trace from the Linux host:
go1.14.trace.zip
If you open the tracer UI for the trace and look at the "User-defined tasks" page you see that most of the timings for the highFreq work fall in the two buckets straddling the 1ms frequency it runs at, but there are a small number of outliers on the high side as seen below.
If we drill into the outlier in the 15ms bucket we see this trace log that shows the task did not wake up until more than 11ms after it's deadline, which is more than 14ms past when the timer was set to fire. After it finally woke up it had to do a lot of work to make up for the missed events. In our real application we cannot afford to miss more than four events like this. Go 1.13 achieves that goal far more consistently, as we will see later.
From the above trace it is useful to take note of the goroutine ID (9) and that the sleep started at 4.006234152 seconds into the trace. Opening the "View trace" page from the trace UI home page and navigating to that time we can see what happened in the program to cause the timer latency and that the scheduler missed many opportunities to do a better job.
(click the image for full resolution)

In the above screen shot G9 goes to sleep just before G10 is scheduled on the same P. G10 monopolizes the P for several milliseconds before yielding and only then does the scheduler check the timers and schedule G9 again, albeit very late.
The arrow labeled "another late wakeup" pointing to G11 shows another example. In this case G12 runs long enough to get preempted by the sysmon thread and allow G11 time to run, also late. But it also shows that another P steals G12 almost immediately to complete its processing.
Throughout this time there are plenty of idle P's available to do work, but the scheduler rules prevent them them from stealing the available expired timers.
Comparison to Go 1.13
Here is a trace file using the Go 1.13 build and collected the same way.
go1.13.trace.zip
The task histograms do not have the same outliers. It is also noteworthy that all of the highFreq goroutines performed exactly 5,000 sleeps during the 5 second trace, an indication that the inner loop never had perform any catch up iterations.
The trace timeline shows goroutines sleeping just before a longer task but getting picked up by a different P on schedule.
(click the image for full resolution)
Summary
The new timer implementation in Go 1.14 does a great job reducing the overhead of servicing the timer queues, but the decision not to steal timers from P's not marked for preemption introduces opportunities for timer latencies of several milliseconds even when there are idle P's available to do the work.
We would like the runtime to give goroutines waiting on an expired timer the same priority for work stealing as runnable goroutines already in the run queue. Prior versions of Go exhibited that property because the timer queue was serviced by a goroutine on par with all other goroutines.
cc @ianlancetaylor
Also, could this behavior be part of what's going on in #36298?
The text was updated successfully, but these errors were encountered: